GBDT
思路: 使用多个cart树,对数据进行拟合,每个树都用来拟合上一步的负梯度(后面解释),最后将每一个cart树的结果累加(加权),得到预测结果。
需要理解的几个问题:
- 为什么拟合负梯度,和拟合误差一样吗?(回归问题)
- 如何拟合负梯度
- 如何确定每个叶子节点的值
- 加权求和是什么意思
- 正则化的问题
拟合负梯度(解决前两个问题)
首先对于一个函数来说,沿着负梯度方向会让函数值降低,对于一般问题,损失函数L是关于参数$\theta$ 的函数,一般做法是对参数求导,然后更新参数,得到更好的决策函数,进而降低误差。对于GBDT来说我们提升的不是参数$\theta$ 而是决策函数本身(换句话说参数就是树本身),具体来说。针对损失函数的:
一般方法的损失更新:
对于GBDT的损失更新:
所以构建GBDT树的过程:
初始:假定初始的$f_0$ 是把所有的输入都预测为0,那么通过损失函数对f的导数的解析式可以得到负梯度的方程$- \left. \frac{dL}{df} \right|_{f={f_0}}$ ,_ 输入$f_{0}$ 就是初始cart树预测的结果(也就是0),
构建第二棵树: 在上一步的基础上计算得到了负梯度,将负梯度作为新的label ,按照cart 树的构造方法,得到第二棵树,并为每个叶子节点确定输出的值(后面介绍)。然后更新下一个负梯度$- \left. \frac{dL}{df} \right|_{f={f_1}}$ ,_ 其中$f_1$ 是这第二棵树的预测结果。用新的到的负梯度作为新的label ,
如此迭代下去……
通过导数的计算已经包含了L的信息 也就是原始label 的信息。
在来说一下误差和负梯度的问题(这里的误差是只真实y与预测的$\hat y$ 的差的绝对值 ),当L损失函数为均方误差时,L对f 的导数就是这个误差,所以用mse 作为损失函数的时候,每次更新的负梯度就是求这棵树对$x_i$ 的预测与这棵树的输入 label 的差的绝对值。
针对分类问题也是一样的,二分类问题可以看作是对于每一个类别概率的回归,每个叶子节点的值代表一个连续值,通过类似sigmoid转化成概率,此时对于目标函数一般使用对数似然损失函数$y\epsilon \{-1,1\}$
多分类 同理 类似softmax
用一阶段泰勒展开式,更新参数或者方程,就是沿着负梯度更新,二阶泰勒展开呢 就是用负梯度除以二阶导数的方向更新,GBDT只用了一阶,Xgboost用的二阶

如何确定每个叶子节点的值
找到一个值c,当这个叶子节点中的所有样本都被预测为c时,对于该叶子节点中的每个样本x,计算其误差,使得误差的累加和最小,那么c为这个叶子节点的值。
如何正则(权重)
加入正则项:对于个树,给一个权重v(0到1之间), 预测结果要乘以v ,才是该树的最终预测结果。
抽样,确定超参数(树的深度等参数)
cart树的剪枝等
")
GBDT与随机森林
- 组成随机森林的树可以是分类树,也可以是回归树;而GBDT只能由回归树组成。
- 组成随机森林的树可以并行生成;而GBDT只能是串行生成。
- 对于最终的输出结果而言,随机森林采用多数投票等;而GBDT则是将所有结果累加起来,或者加权累加起来。
- 随机森林对异常值不敏感;GBDT对异常值非常敏感。原因是当前的错误会延续给下一棵树。
- 随机森林对训练集一视同仁;GBDT是基于权值的弱分类器的集成。
- 随机森林是通过减少模型方差提高性能;GBDT是通过减少模型偏差提高性能。
- RF不需要进行数据预处理,即特征归一化。而GBDT则需要进行特征归一化。
为什么RF的树深度比GBDT深很多
对于Bagging算法来说,由于我们会并行地训练很多不同的分类器的目的就是降低这个方差(variance) ,因为采用了相互独立的基分类器多了以后,h的值自然就会靠近.所以对于每个基分类器来说,目标就是如何降低这个偏差(bias),所以我们会采用深度很深甚至不剪枝的决策树。
对于Boosting来说,每一步我们都会在上一轮的基础上更加拟合原数据,所以可以保证偏差(bias),所以对于每个基分类器来说,问题就在于如何选择variance更小的分类器,即更简单的分类器,所以我们选择了深度很浅的决策树
xgboost
思路与GBDT类似,可以说是在基础上更新的新方法,加入了正则,二阶泰勒展开信息等,具体差别后面总结。
目标函数与正则项
loss 函数由二阶泰勒展开近似代替,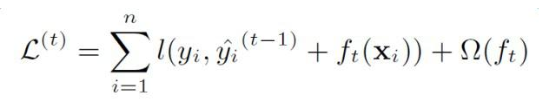
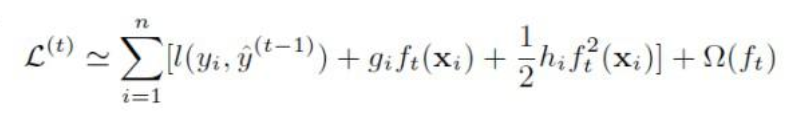
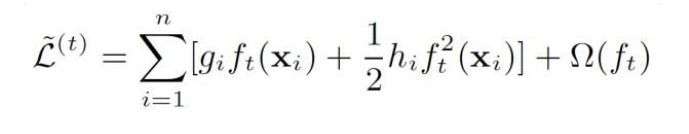
通过求目标函数(二次函数)的极值点的到$L $ 的最小值,以此作为打分函数的依据(分裂节点的依据)。
在GBDT原有的loss 的基础上,增加了正则项: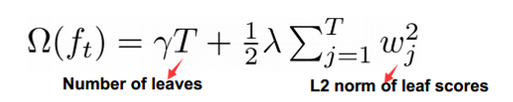
算法流程
与GBDT一样,不同点是算法的目标函数,以及分裂每个节点的方法。
和传统的boosting tree模型一样,xgboost的提升模型也是采用的残差(或梯度负方向),不同的是分裂结点选取的时候不一定是最小平方损失。
对于稀疏值,缺失值
通过分别计算假设其属于$G_L$ 或者属于$G_R$ 选择最合适的。
GBDT 与 xgboost
xgboost 支持自定义目标函数 只要二阶可导就行。
怎么防过拟合
目标函数中的正则项,行抽样,列抽样,shrinkage(在一个树结束的结果上乘以一个0-1之间的数)
xgboost与深度学习对比
同的机器学习模型适用于不同类型的任务。深度神经网络通过对时空位置建模,能够很好地捕获图像、语音、文本等高维数据。而基于树模型的XGBoost则能很好地处理表格数据,同时还拥有一些深度神经网络所没有的特性(如:模型的可解释性、输入数据的不变性、更易于调参等)。